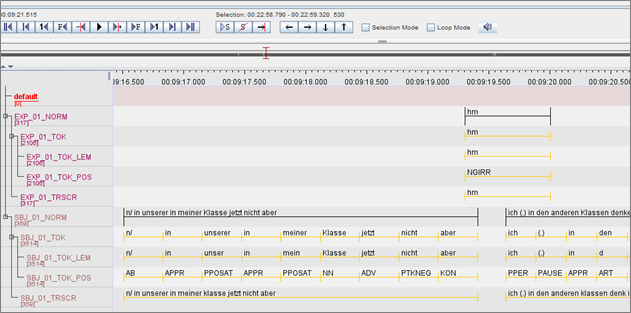
Annotation
Im Unterschied zur Transkription, die eine Kleinschreibung vorsieht, erfolgte bei der Normalisierung der mündlichen Daten eine orthographische Transkription nach der Dudenrechtschreibung. Anschließend erfolgte auf der Ebene der manuellen Normalisierung die automatische Tokenisierung, wobei die einzelnen Tokens wiederum automatisch in Lemmata und Wortarten klassifiziert wurden. Diese Gliederung erfolgte bei jedem einzelnen Sprecher.